DynamoDB virtual table
Published on Nov 28, 2020
ตอนแรกจดไว้ใน Twitter แล้วคิดว่ายังมีให้เขียนได้อีกเลยย้ายมาลงในนี้เลยดีกว่า
ระบบอีเมล์ที่ดูแลอยู่ตอนนี้ฐานข้อมูลที่ใช้เป็น DynamoDB เหตุผลที่เลือกเพราะถูกและดูแลง่าย ผ่านมาสองปีแบบไม่ต้องแตะเลยมันก็ทำงานได้โดยไม่ต้องปวดหัวคอยอัพเกรดหรือแก้ parameter อะไร จนปีนี้ต้องมาเพิ่มความสามารถให้ระบบนี้เลยต้องเข้ามาดูอีกครั้ง ก็มีเรื่องจุกจิงของฐานข้อมูลนี้พอสมควรแต่ก็เป็นเพราะ schema, index และข้อมูลที่ใส่ลงไปด้วย เลยทำให้แก้ยาก
วิธีเก็บข้อมูลลง DynamoDB ก็ไม่มีอะไรซับซ้อนเวลาสร้างเราแค่บอกว่าฐานข้อมูลมี hash key (key ที่ไว้ให้ฐานข้อมูลเลือก partition) กับ range key สำหรับเรียงลำดับข้อมูลใน partition ที่จะมีหรือไม่มีก็ได้ จากนั้นเราก็ใส่ข้อมูลลงไปโดยที่ข้อมูลอาจจะมีมากกว่าที่ระบุใน schema ได้เช่น key คือ email และ created_at เวลาใส่ข้อมูล สามารถใส่ email, created_at, plan, mailing_list ได้ ข้อมูลที่ไม่ได้ประกาศไว้ใน key จะถูกแยกไปใน column ของตัวเองเพียงแต่เราจะไม่สามารถ search โดย column นั้นได้
แล้วถ้าข้อมูลที่เราใส่มีหลายแบบเช่น
id,user_created_at,email,planid,plan_created_at,plan_name,pricingid,scored_at,user_id
ถ้าเป็น rational database หรือ document database ทั่วไปก็จะแยกข้อมูลเหล่านี้ลง table หรือ document แยกไปเป็น unit ของตัวเองเลย DynamoDB ก็ทำอย่างนั้นได้เหมือนกัน
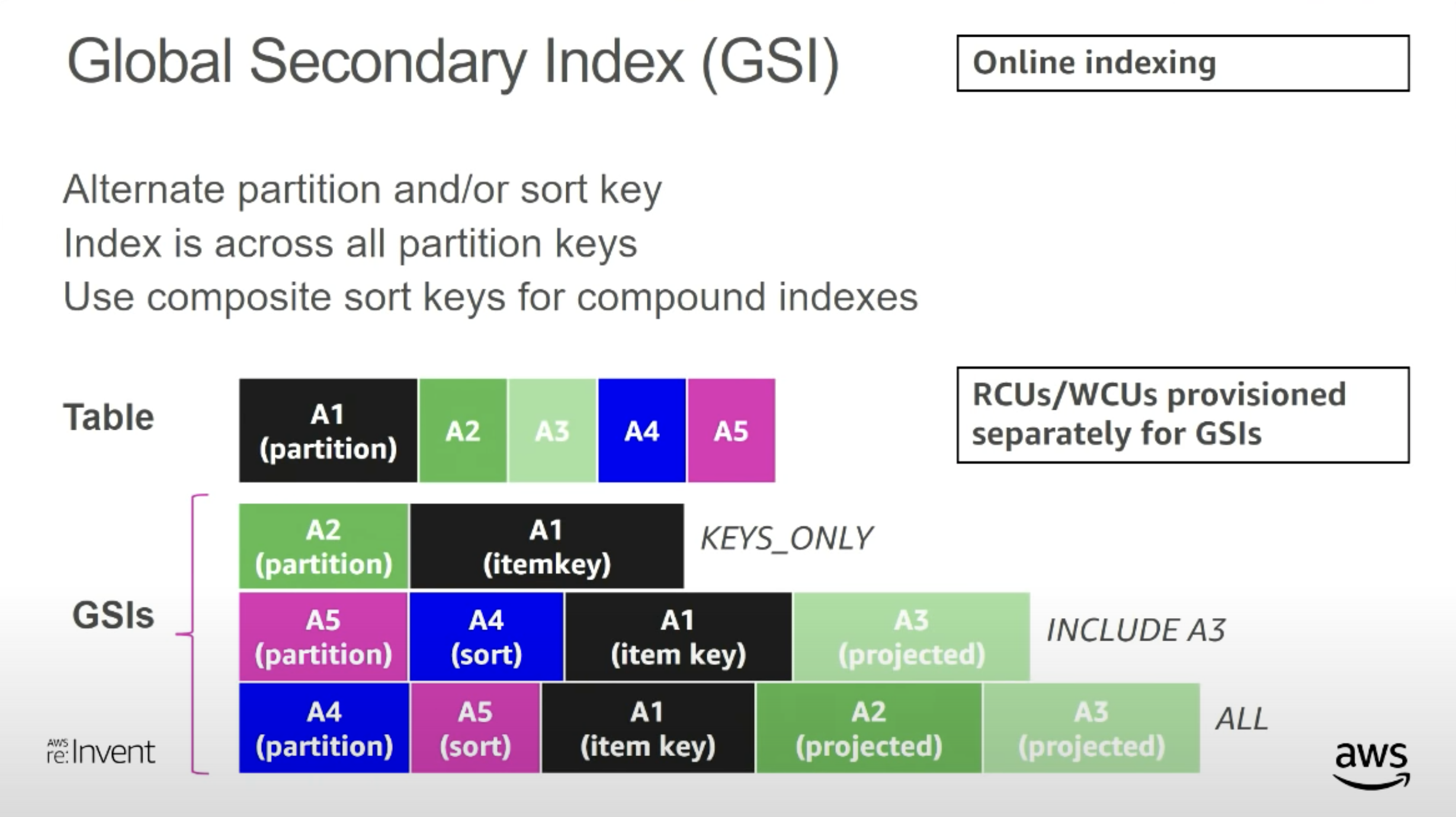
อีกวิธีที่ทำได้คือใช้ Global Secondary Index (GSI) แยกข้อมูลบน table ลง index ที่ DynamoDB ทำท่านี้ได้ก็เพราะ column ของ table นั้นไม่ตายตัว เมื่อทำ Index บน column เฉพาะของข้อมูลแต่ละแบบแล้ว ข้อมูลใน index ก็จะเหมือน table แยกไปเลย ข้อเสียของวิธีนี้คือ ค่า write เพิ่มขึ้นเท่าตัวเพราะต้องจ่ายให้กับ Global Secondary Index ด้วยและกับจำนวน Table ที่ต้องจัดการ
ข้อระวังอย่างหนึ่งของการใช้ GSI นอกจาก cost คือข้อมูลที่ใส่เข้าไปในฐานข้อมูล ต้องแยก column ที่ index ชัดเจนเช่นจากตัวอย่างด้านบน column ที่เป็น range key จะไม่ใช้ชื่อซ้ำกันเลย เพราะถ้าใช้ซ้ำกันแล้ว ข้อมูลสองประเภทจะไปปรากฏใน GSI ที่กำหนด key ไว้ว่าใช้ column นั้น เวลาแยกจะใช้ Hash Key หรือ Range Key เพื่อแยก view ก็ได้ขอแค่ระวังเรื่องข้อมูลที่จะใส่ลงไปเท่านั้น
ข้อเสียอีกอย่างสำหรับวิธีนี้คือ ถ้าฐานข้อมูลมีขนาดใหญ่แล้ว จะแก้ไข index ใช้เวลานานมากเพราะเวลาสร้าง index ใหม่ DynamoDB จะเอาไปอ่าน table แล้ว fill ลง secondary index ให้หมด เพราะฉะนั้นยิ่งฐานข้อมูลใหญ่ยิ่งใช้เวลานาน แต่ประเภทข้อมูลที่ใช้ในระบบอีเมล์เป็นประเภท moving data คือไม่จำเป็นต้องเก็บไว้ฐาวรเช่น จำนวน Bounce/Complaint ในช่วงเวลาหนึ่ง แล้ว DynamoDB มี feature TTL ที่ลบข้อมูลให้อัตโนมัติ เลยเอามาช่วยจำกัดขนาดได้ (แต่ตอนนี้มีข้อมูลประเภทนึงลืมใส่ TTL แล้วมันผ่านมาสองปีเลยต้องไปหาทางลบ ง่ายสุดก็คง query มาใส่ข้อมูลประเภทใหม่แล้วลบ index เดิมซะ)
สรุป
- ถ้าไม่เรื่องมากเรื่องจำนวน Table ก็แยก Table ไปเลยซะ cost ถูกกว่า
- GSI สามารถเอามาใช้เป็น table view แยกข้อมูลจาก table ได้เพราะ DynamoDB ไม่มี schema
- ถ้าจะใช้ GSI ต้องคิดว่ามันมี double write cost (แต่มันถูกจนไม่ต่างจากแยก table ไปเท่าไหร่)
- จำกัดขนาด table ด้วย TTL ไว้ยิ่งใหญ่ถ้ามีแก้ GSI หรือเพิ่มประเภทข้อมูลทีหลังเสียเวลานาน